contact for pricing
GPU-based ML deployment platform
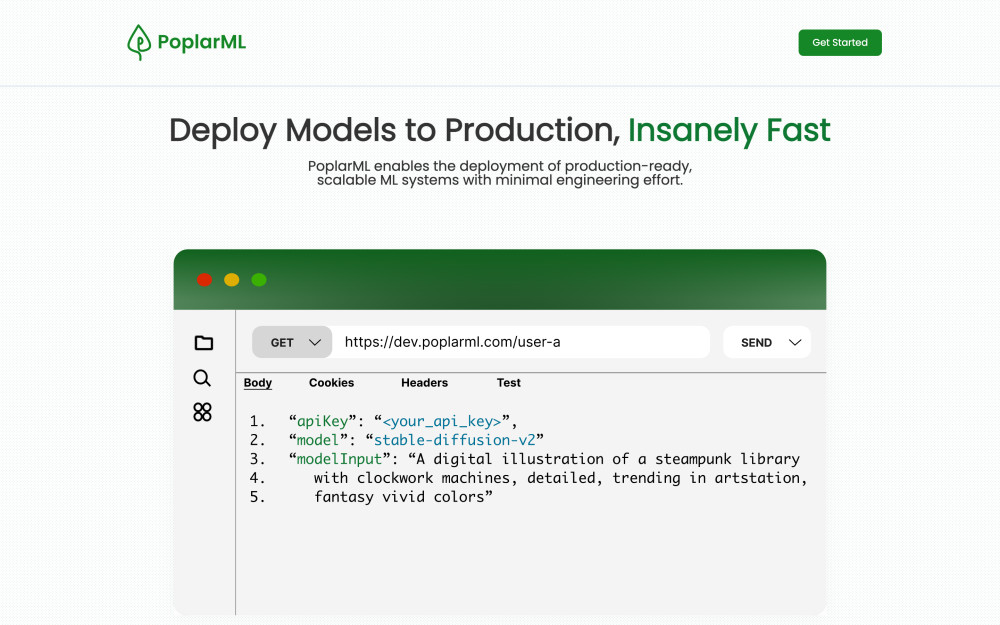
PoplarML is a tool that simplifies the deployment of production-ready, scalable machine learning systems with minimal engineering effort. With just one command, users can deploy any machine learning model to a fleet of GPUs as a ready-to-use and scalable API endpoint. PoplarML is framework-agnostic, allowing users to bring their Tensorflow, Pytorch, or JAX model to be deployed seamlessly. The tool enables real-time inference by invoking a model through a REST API endpoint. PoplarML offers an easy-to-use command-line interface tool that deploys machine learning models with minimal engineering effort. The platform is designed to help users reduce time-to-market, and streamline their machine learning deployment processes. PoplarML simplifies deployment workflows by providing a platform for automating the deployment process. It scales effortlessly to accommodate new features and workflows as users need them. PoplarML is built for diverse teams, including developers, data scientists, and machine learning engineers.Features:
- Simplifies the deployment of production-ready and scalable ML systems with minimal engineering effort
- Allows users to deploy any machine learning model to a fleet of GPUs with just one command
- Accepts models built on Tensorflow, PyTorch, or JAX frameworks
- Enables real-time inference through a REST API endpoint
- Offers an easy-to-use CLI tool for deploying machine learning models with minimal engineering effort
- Designed to help users reduce time-to-market and streamline their machine learning deployment processes
- Simplifies deployment workflows and automates the deployment process
- Built for diverse teams, including developers, data scientists, and machine learning engineers
- Scales effortlessly to accommodate new features and workflows as users need them