GPU Everything. Run anything Dockerized. Run autoscale Inference. Save costs 50-90%.
Serverless GPU inference for ML models Pay-per-millisecond API to run ML in production.
PoplarML enables the deployment of production-ready, scalable ML systems with minimal engineering effort. Lets you deploy any machine learning model to a fleet of GPUs as a ready-to-use and scalable API endpoint with one command.
Rent Cloud GPUs from $0.2/hour. Save over 80% on GPUs. GPU rental made easy with Jupyter for PyTorch, Tensorflow or any other AI framework.
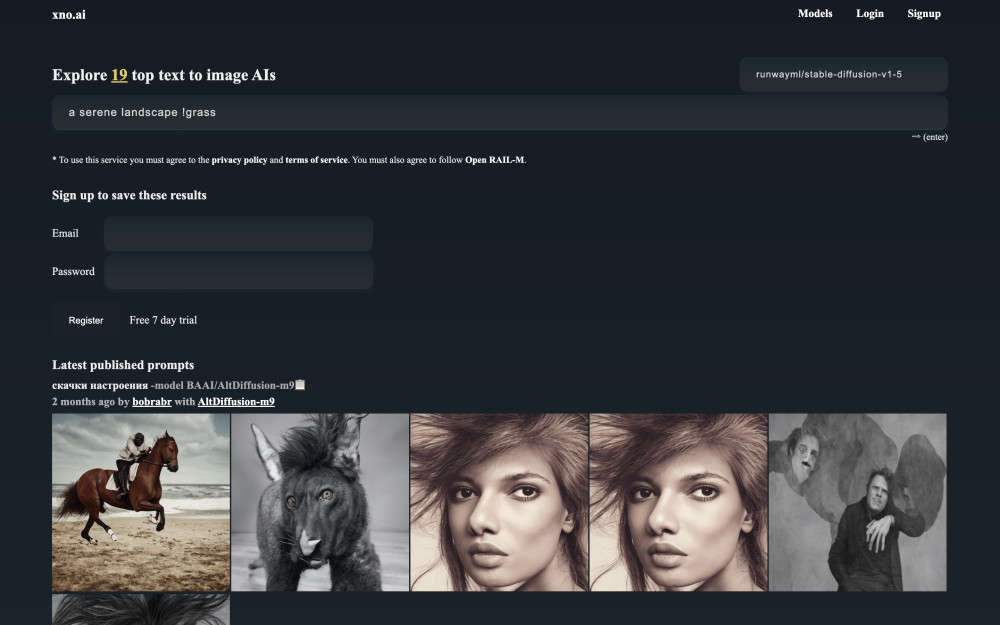
Explore 19 top text to image AIs with 39 GPUs.